
AYM Başvuruları
kabul edilebilirlik ve sonuç bakımından değerlendirilir

Deneyim
Alanında Üst Düzey Uzmanların Birleşimi
Proje ekibinin her biri yapay zeka alanında birçok makale, kitap ve proje yapmış olmakla birlikte hukuk alanındaki bilim adamları bir arada çalışmaktadır. Projeye farklı kuruluşlardan hem araştırmacı düzeyinde hem de projeye farklı düzeylerde katkılar vardır. Proje ekibinin detayı için tıklayınız.
Proje Misyonu
Anayasa mahkemesinin bireysel başvurularını öncelikle kabul edilebilirlik açısından sonrasında ise hak ihlali olup olmadığı açısından tahmin edilir.
- Başvurunun Kabul Edilip Edilmeyeceği
- Hak İhlali Olup Olmadığı
B
Ekibin Toplam Atıf Sayısı
— Proje Ekibi —
-

Yürütücü
Sakarya Üniversitesi İşletme Fakültesi Yönetim Bilişim Sistemleri Anabilim Dalında Doç. Dr. olarak çalışmaktadır.
Emrah AYDEMİR
Danışman
Sakarya Üniversitesi Hukuk Fakültesi Ceza ve Ceza Muhakemesi Hukuku Anabilim Dalında Arş. Gör. olarak çalışmaktadır.
Yusuf KAÇAR
Araştırmacı
Sakarya Üniversitesi İşletme Fakültesi Yönetim Bilişim Sistemleri Anabilim Dalında Doç. Dr. olarak çalışmaktadır.
Halil İbrahim CEBECİ
Araştırmacı
Fırat Üniversitesi Teknoloji Fakültesi Adli Bilişim Mühendisliği Anabilim Dalında Doç. Dr. olarak çalışmaktadır.
Türker TUNCER
Araştırmacı
Fırat Üniversitesi Teknoloji Fakültesi Adli Bilişim Mühendisliği Anabilim Dalında Doç. Dr. olarak çalışmaktadır.
Şengül DOĞAN
Araştırmacı
Sakarya Üniversitesi Hukuk Fakültesi Milletlerarası Hukuk Anabilim Dalında Dr. Öğr. olarak çalışmaktadır.
Sezercan BEKTAŞ
Araştırmacı
Sakarya Barosuna
kayıtlı avukat olarak
çalışmaktadır.
Asuman ÖCAL
Bursiyer
Marmara Üniversitesinde Kamu Hukuku alanında doktora öğrencisidir.
Görkem KAYACIK
Bursiyer
Sakarya Üniversitesinde Özel Hukuk alanında yüksek lisans öğrencisidir.
Sena DER
Bursiyer
Sakarya Üniversitesinde Yönetim Bilişim Sistemleri alanında doktora öğrencisidir.
Burak ARSLAN
— Proje Hakkında —
Bu proje, esas olarak, adalete erişimin önündeki engellerin kaldırılması, hukuki güvenlik ve belirliliğin geliştirilmesi ve hukuk uygulayıcılarının karşılaştığı pratik problemlerin çözülmesinin, yapay zekâ teknolojilerinin kullanılması suretiyle oluşturulacak yardımcı araçların hukuk alanında istihdam edilmesi suretiyle mümkün olabileceği tezinden hareket etmektedir. Bu kapsamda, projenin temel amacı, kişilerin, Anayasa Mahkemesi’ne bireysel başvuru sürecinden önce, oluşturulacak “Hak İhlali Karar Tahmin Motoru” (HAKTAM) sayesinde başvurusunun kabul edilebilir olup olmadığını ve kabul edilebilir olanların hak ihlali olup olmadığını önceden öngörmesini sağlamaktır. Bu projenin bir diğer amacı ise, Anayasa Mahkemesi dışındaki mahkemelerin kararlarının hangi formatta olması gerektiğini ve bu kararların dijitalleştirilmesinin yol açabileceği faydaları ortaya koymaktır. Bir diğer önemli amaç ise, yapay zekâ temelli teknolojilerin Türk hukuk sisteminde de kullanılabileceğini ortaya koymaktır.
Bu amaçlar çerçevesinde, kabul edilebilirlik ve esas yönünden iki aşamalı olarak yüksek tahmin kapasitesine sahip yapay zekâ temelli bir algoritma kurmak ve bunu çevrimiçi ücretsiz bir platformda herkesin kullanımına sunmak hedeflenmektedir. Aynı zamanda bu süreçte yapılacak çalışmalarda, Anayasa Mahkemesi kararlarını yapay zekâ incelemesine uygun hâle getiren unsurlar tespit edilip diğer mahkeme kararlarının da hangi formatta düzenlenmesi gerektiğine ilişkin bir teklif oluşturulması bu projenin önemli hedeflerinden bir diğerini oluşturmaktadır. Her ne kadar mahkeme kararlarının tahmin edilmesine yönelik çalışmalar literatürde mevcut ise de bu proje gerek kullandığı yöntem gerekse ortaya koyduğu ürün ve bu ürün vesilesiyle elde edilebilecek faydaları yönünden diğer çalışmalardan ayrılmakta ve özgün yönünü ortaya koymaktadır.
ULUSAL KAZANIMLAR, TOPLUMSAL VE KAMUSAL FAYDA POTANSİYELİ
Birleşmiş Milletler’in Türkiye’nin sürdürülebilir kalkınması için yayınladığı ve 2030’a kadar ulaşılmasını temenni ettiği amaçlardan biri herkes için adalete erişimin sağlanmasıdır (Birleşmiş Milletler Türkiye, 2021). Adalete erişimin önündeki en büyük engellerden biri ise, adlî makamlar yoluyla çözümlenmek istenen uyuşmazlık sayısında son yıllarda yaşanan devasa artıştır. Bu durum, hâlihazırda oldukça uzun olan dava sürelerinin daha da artmasına yol açmaktadır. Yıllar süren uyuşmazlıklar hem uyuşmazlığın taraflarını karşılıklı olarak yıpratıp toplumsal huzursuzluğa yol açmakta hem de devletin üç erkinden biri olan yargıya yönelik hâlihazırda oldukça düşük olan güvenin daha da aşağıya çekilmesine sebebiyet vermektedir (Sosyal Demokrasi Vakfı, 2019).
Bu kapsamda, en yüksek yargı makamı olarak Anayasa Mahkemesi’nin işlerliğini sürdürebilmesi için iş yükünün azaltılması gerekliliği sık sık vurgulanmaktadır (Arslan, 2021). Anayasa Mahkemesi’ne bireysel başvuru yolunun açıldığı 2012 yılından bu yana, mahkemeye 320 binden fazla bireysel başvuru yapılmıştır (Anayasa Mahkemesi Başkanlığı, 2021). Bir karşılaştırma yapmak adına belirtmek gerekirse, 1951 yılından bu yana bireysel başvuru yolu bulunan Almanya’da, 70 yıllık sürede Federal Almanya Anayasa Mahkemesi’ne yapılan bireysel başvuru sayısı 240 bin civarındadır (Federal Constitutional Court, 2021). Bu kapsamda, yapay zekâ ve hukuk alanında uzman kişilerin bir araya gelmesiyle hazırlanacak olan işbu proje, Anayasa Mahkemesi’nin iş yükünün azaltılmasına ve bu suretle yargıya olan güvenin artırılmasına katkıda bulunulacaktır. Buradan alınacak başarılı sonuç ile Anayasa Mahkemesi’nin ve diğer yargı organlarının yapısına ve işleyişine ilişkin gelecekte oluşturulacak kamu politikalarının yapay zekâ temelli dijitalleşmeye yönelmesi hedeflenmekte ve bu yolla toplumsal ve kamusal faydanın elde edilmesi beklenmektedir.
Diğer taraftan, bu projenin çıktısı niteliğindeki “Hak İhlali Karar Tahmin Motoru” (HAKTAM) sayesinde, yapay zekâ temelli teknolojilerin sosyal hayatın davranış kodlarını düzenleyen hukuk kuralları çerçevesinde de aktif olarak kullanılabileceği ortaya konmuş olacaktır. Böylece, bu proje hem yarattığı ürün ile pratik olarak teknolojik dönüşüme katkıda bulunacak hem de yayınlanması hedeflenen makalede teorik düzeyde yapay zekânın hukuk uygulamasına etkileri aktarılarak bu alanda yapılabilecek farklı teorik ve pratik çalışmalara ışık tutulacaktır.
Bu proje bir başka yönüyle, proje çağrı metninde dönüşümsel çözümler gerektiren bir güçlük alanı boyutu olarak ifade edilen “insan odaklı dijitalleşme” idealine katkı sunma potansiyeline sahiptir. Şöyle ki, yapay zekâ temelli teknolojiler, hâlihazırda dünyanın pek çok farklı yerinde hukukun farklı alanlarında aktif bir şekilde kullanılmaktadır. Teknolojik olarak gelişmiş ülkelere kıyasla, Türkiye’de hukuk alanında gerek yapay zekânın kullanımı ile ilgili teorik araştırmalar gerekse yapay zekâ temelli teknolojilerin pratik olarak kullanımı oldukça zayıftır. Bu proje hem teorik altyapısı hem pratik hayata yansıyan uygulaması ile bu alanda çalışan kişilere örneklik teşkil edecek ve “insan odaklı dijitalleşme” yolunda farklı disiplinlerin bir araya gelerek hukukun daha etkin, daha verimli ve herkesin erişimine daha fazla açık hâle gelmesi için çalışmaların yapılmasına katkıda bulunacaktır.
“Makine öğrenimi” (Machine Learning – ML) ve “doğal dil işleme” (Natural Language Processing – NLP) tekniğine dayanılarak geliştirilen yapay zekâ teknolojilerinin daha yaygın olarak kullanılabilmesi için belli standartların sağlanması şarttır. Bu proje Anayasa Mahkemesi kararlarının büyük oranda aynı şablon kullanılarak yazılmasından ve önemli kararların dijital ortamda gelişmiş bir karar arama motoru aracılığıyla paylaşılmasından ileri gelmektedir. Buradan hareketle şunu ifade etmek gerekir ki, yapay zekânın adlî süreçlerde daha aktif olarak kullanılabilmesi için diğer mahkeme kararlarının da Anayasa Mahkemesi kararlarının sahip olduğu tertibe sahip olması ve uygun bir formatta dijital ortamda paylaşılması gerekmektedir. Bu açıdan proje, Anayasa Mahkemesi’nin dışında diğer mahkemelerin kararlarının da hangi standartlarda olması gerektiğine ve dijital ortamda paylaşılmasına ilişkin yapılacak hukukî düzenlemelere temel sağlanmış olacaktır.
YENİLİKÇİ YÖNÜ
Yapay zekânın hukuk alanında çok farklı kullanım şekilleri mevcuttur. Hukuki metinlerin otomatik olarak özetlenmesi, bu metinlerden bilgi ayıklanması (Nguyen vd., 2018), kaynakların otomatik olarak kategorize edilmesi, istatistiksel olarak analizlerin yapılması (Medvedeva vd., 2020), hâkimlerin cinsiyeti ve politik arka planının onların karar verme süreçlerine olan etkisinin hesaplanması (Frankenreiter, 2016; Hausladen vd., 2020; Rachlinski & Wistrich, 2017), bir sorguyla ilintili kanunların bulunması (Kim vd., 2017; Minh-Tien Nguyen, 2016) gibi faaliyetlerin gerçekleştirilmesi için yapay zekâ aktif olarak hukuk alanında kullanılmaktadır.
Yukarıdaki kullanım alanlarına ek olarak, yapay zekâ ayrıca mahkeme kararlarının tahmin edilmesinde de kullanılabilmektedir. Lawlor (1963), 1963 yılında yayınladığı oldukça ileri görüşlü bir makalesinde, gelecekte bilgisayarların yargı kararlarını analiz edebileceğini ve sonuçlarını tahmin edebileceğini ifade etmiştir (Lawlor, 1963). Onun çalışmasının üzerinden 50 yıldan fazla sürenin geçmesinden sonra, bugün, “doğal dil işleme” ve “makine öğrenimi” teknolojileri hukuki metinleri analiz etme ve bu analiz sayesinde mahkeme kararlarını başarılı bir şekilde tahmin edebilme imkânını sunmaktadır (Aletras vd., 2016). Nitekim bu projenin de temel amacı, NLP ve ML teknolojilerinin kullanılması suretiyle, 2012 yılından itibaren Anayasa Mahkemesi’ne yapılan insan haklarının ihlal edildiği iddiasını içeren bireysel başvuruların kabul edilebilirlik ve esas yönünden Anayasa Mahkemesi tarafından muhtemel olarak nasıl sonuçlandırılacağının önceden yüksek bir başarı oranında tahmin edilmesini sağlayacak yapay zekâ temelli bir uygulamanın geliştirilmesidir.
Özellikle geçtiğimiz yıllarda, mezkûr tekniklerin kullanılması suretiyle çeşitli ulusal ve uluslararası mahkemelerin kararlarının tahmin edilmesine yönelik önemli sayıda çalışma yayınlanmıştır. Örneğin, Aletras vd. (2016)’nin yaptığı Avrupa İnsan Hakları Mahkemesi’nin (AİHM) kararlarını konu alan bir çalışmada, Destek Vektör Makineleri (Support Vector Machine) adlı bir sınıflandırıcı kullanılarak, 584 karar üzerinden Avrupa İnsan Hakları Sözleşmesi’nin 3, 6 ve 8’inci maddelerinin ihlal edilip edilmediği (binary classification – ikili sınıflandırma) tahmin edilmeye çalışılmış ve %79 oranında başarı yakalanmıştır (Aletras vd., 2016). Yine AİHM kararlarının konu alındığı ve benzer bir yöntemin takip edildiği başka bir çalışmada ise, daha geniş kapsamlı (3.132 karar) ve dengeli bir veri seti kullanılmış ve bir önceki çalışmanın aksine kararlarda yer alan, mahkemenin ilgili olay ile alâkalı hukuki argümanlarına yer verdiği, “hukuk” başlığı makineye öğretilmemiştir. Sonuç olarak, %77 oranında başarı sağlanmıştır. Araştırmacılar, bir önceki çalışmaya göre kendi çalışmalarının, daha geniş kapsamlı veri seti kullanmasından ötürü, temsil kabiliyetinin daha yüksek olduğunu ve kararlarda yer alan “hukuk” başlığını geliştirdikleri sisteme öğretmemeleri nedeniyle bu sistemin daha az “önyargılı” olduğunu ifade etmişlerdir (Medvedeva vd., 2020).
Yargı kararlarının önceden tahmin edilmesine ilişkin çalışmalar AİHM ile sınırlı değildir. Örneğin, Katz vd. (2014)’nin yaptığı çalışmada, Amerika Birleşik Devletleri Yüksek Mahkemesi’ne ait (US Supreme Court) 28.000’den fazla karar kullanılmış ve gerek bütün olarak yargı kararı gerekse hâkim bazlı tahminde bulunulmaya çalışılmıştır. Sonuç olarak bu çalışma, hâkimlerin oyunu tahmin etme konusunda %71,9; bütün olarak mahkeme kararını tahmin etme konusunda ise %70,2 oranında başarı elde etmiştir (Katz vd., 2014). Lage-Freitas vd. (2019) ise, 4.403 karardan oluşan veri seti ile Brezilya’nın temyiz mahkemesinin kararlarını tahmin etmeye çalışmış ve %79 oranında başarıya ulaşmıştır (Lage-Freitas vd., 2019). Literatürde şahit olduğumuz en yüksek başarı oranı ise, Şulea vd. (2017)’nin çalışmasına aittir. Fransız Yüksek Mahkemesi’nin 1800’lü yıllardan bu yana verdiği 126.000’den fazla kararı veri seti olarak alan bu çalışma, diğer çalışmaların aksine iki bileşenli değil altı ve sekiz bileşenli iki ayrı sınıflandırma görevi üzerine çalışmış ve %97’ye varan bir başarı oranına ulaşmıştır (Şulea vd., 2017). Bu çalışmanın bu denli yüksek bir başarıya ulaşmasında, veri setlerinde yer alan kararların sayısı ve niteliğinin rol oynadığını söylemek mümkündür. Bunun yanında, NLP metodunun Fransızca gibi çekimli dillerde, Türkçe gibi eklemeli dillere nazaran daha başarılı sonuçlar vermesi de bu sonuca etki eden nedenler arasında sayılabilir. Diğer taraftan, Filipin Yüksek Mahkemesi üzerine çalışma yapan Virtucio vd. (2018) ise 27.000’den fazla kararı içeren veri setine sahip olmasına rağmen literatürde yer alan en düşük sonuçlardan biri olan %59 oranını elde etmiştir. İlgili yazarlar, bunun sebebinin ellerindeki mahkeme kararlarının diğer ülkelerde yer alan yüksek mahkemelerin kararlarına nispetle yapısal olarak daha zayıf olmasına, kararların oldukça çeşitli hukuk alanlarıyla ilişkili bulunmasına ve kararları daha derli toplu bir şekilde elde edebilecekleri bir platformun olmamasına bağlamaktadırlar (Virtucio vd., 2018).
Bu çalışmaların yanı sıra gerek yüksek mahkemelerin gerekse daha alt derecedeki mahkemelerin ceza hukuku, özel hukuk, aile hukuku gibi alanlarda daha önce verdiği kararlara dayanılarak karar tahminleri yapılmaya çalışılmış ve çalışmaların önemli bir kısmında tatmin edici sonuçlara ulaşılmıştır (Chen vd., 2019; Goel vd., 2019; Kowsrihawat vd., 2018; Li vd., 2018; Long vd., 2018; O’Sullivan & Beel, 2019; Yuan, 2020).
Gerek bizim bu projede kullanmayı hedeflediğimiz yöntemin benzerlerini kullanmaları gerekse Anayasa Mahkemesi’nin kararlarını konu almaları bakımından literatürde yer alan iki çalışma ile bu proje arasındaki benzerliklerin ve farklılıkların ortaya konulması, bu projenin yenilikçi yönünü ortaya çıkartması bakımından önem arz etmektedir. Mayıs 2021’de yayınlanan bir araştırmada, “genel ahlak” (92 karar) ve “ifade özgürlüğü” (388 karar) konularında yer alan toplamda 480 karar üzerinden bir çalışma yürütülmüş ve oluşturulan sistemin iki bileşenli sınıflandırma görevini (ihlal var ya da yok) başarıyla yerine getirip getiremeyeceği test edilmiştir. Yazarlar, “kabul edilemez” nitelikteki kararları da hak ihlalinin olmadığı sınıfa dâhil etmişlerdir. Araştırmanın ortalama %90 oranında başarıya ulaştığı ifade edilmiştir (Sert vd., 2021). Temmuz 2021’de yayınlanan bir başka çalışmada ise, sadece Anayasa Mahkemesi ile sınırlı kalınmamış, Türkiye’de yer alan birçok yüksek mahkemenin kararları tahmin edilmeye çalışılmıştır. Bizim projemizin konusu ile ilintili olması bakımından belirtmek gerekir ki, Mumcuoğlu vd., 1290 adet (149 ihlal yok, 1141 ihlal var) Anayasa Mahkemesi kararından oluşan bir veri seti kullanmış ve %91,8 oranında başarı yakalamıştır (Mumcuoğlu vd., 2021).
Öncelikle belirtmek gerekir ki, bizim projemiz Sert vd. (2021)’nin yaptığı mezkûr çalışmadan farklı olarak belli bir hak sınıflandırmasına gitmeden (sadece genel ahlak ve ifade özgürlüğü değil) ve kullanılabilir bütün verileri kullanmak suretiyle yekûn olarak mahkeme kararlarını yapay zekâya öğretmeyi ve yine test için kullanılacak mahkeme kararlarını da rastgele seçerek sistemin genel başarısını ölçmeyi hedeflemektedir. Ayrıca, Sert vd. (2021) ve Mumcuoğlu vd. (2021)’den farklı olarak, bu projede öncelikle başvurunun kabul edilebilir olup olmadığı, daha sonra ise esas yönünden potansiyel olarak bir hakkın ihlal edilip edilmediği tahmin edilmesi amaçlanmaktadır. Dolayısıyla bu projede, her biri ikili sınıflandırma görevinden oluşan iki aşamalı bir süreç söz konusu olacaktır. Bu yönüyle bu proje hem kabul edilebilirlik hem de esas yönünden Anayasa Mahkemesi’nin kararlarını tahmin etme kabiliyetine sahip bir sistem geliştirmeyi hedeflemesi bakımından daha kapsayıcı ve daha geniş kapsamlı bir veri seti kullanmayı hedeflemesi nedeniyle de temsil kabiliyeti daha yüksek bir niteliği haizdir. Diğer yandan, kabul edilebilirlik ve esas yönünden iki aşamalı bir tahmin yürüten böyle bir çalışma, bildiğimiz kadarıyla daha önce ne Türkiye’de ne de diğer ülkelerde gerçekleştirilmemiştir. Bu yönüyle proje, literatürde eşsiz bir çalışma örneği sergileyecektir.
Diğer taraftan, Sert vd.’nin (2021) çalışmasında, makineye Anayasa Mahkemesi kararlarında yer alan “başvurunun konusu” ve “değerlendirme” bölümleri öğretilmiştir. Özellikle değerlendirme bölümü, Anayasa Mahkemesi’nin konu hakkındaki görüşünü ayrıntılı olarak açıkladığı bölümdür. Makineye, değerlendirme ve hukuk bölümlerinin öğretilmesi literatürde makinenin “önyargılı” olma potansiyelini yükseltmesi bakımından eleştirilmektedir (Medvedeva vd., 2020). Bu projede ise, Mumcuoğlu vd.’nin (2021) tercihine paralel olarak, kararlarda yer alan “olay ve olgular” bölümünün makineye öğretilmesi ve gelecekte başka kişilerin de mahkemenin ifade ettiği formatta başından geçen hukuki olayları ifade etmesi suretiyle başvurunun kabul edilebilir olup olmadığı ve muhtemel bir hak ihlalinin var olup olmadığının tahmin edilmesi hedeflenmektedir.
Son olarak, Sert vd. (2021)’nin çalışmasında “genel ahlak” kategorisinde yer alan kararlar bakımından, Mumcuoğlu vd. (2021)’nin çalışmasında ise Anayasa Mahkemesinin tüm kararları bakımından kullandıkları veri seti dengesiz olduğu için “veri artırma” (data augmentation) metodu kullanılmıştır. Coulombe (2018), metinlerde veri artırma için metne gürültü ekleme, yazım hataları yerleştirme, kelimelerin eş anlamlıları ile değiştirilmesi, düzenli ifadeler ile açıklama ekleme, söz dizimi ağaçları ile açıklama ekleme, geri çeviri ile açıklama ekleme yöntemlerinin olduğunu söylemiştir. Söz konusu çalışmada bu gibi yöntemlerden hangilerinin kullanıldığı belirtilmemiştir. Bu yöntemlerin tümü verinin temel istatistiklerini ve dağılımını korumaya çalışır. Eğer veri arttırma yalnızca öznitelikleri çıkarılmış bir örneklem üzerinde yapılırsa bu kolaylıkla sınıflandırma algoritmalarının öğrenmesini sağlayacak veri oluşturmak anlamına gelebilir (Coulombe, 2018). Bizim çalışmamızda böyle bir yöntem tercih edilmeyecek, veri seti baştan itibaren elde mevcut olan kullanılabilir veriler üzerinden dengeli bir şekilde oluşturularak gerçeğe daha yakın tahminler üretmeye elverişli bir sistem oluşturulmaya çalışılacaktır.
Yukarıda bahsedilen çalışmaların içeriğinden de anlaşılabileceği üzere, tespit edebildiğimiz kadarıyla bu çalışmaların henüz pratik hayata yansıyan bir uygulaması olmamıştır. Bizim projemiz ise, bugüne kadar yapılan çalışmaların aksine, yapılacak araştırmaların sonunda bir ürün çıkartmayı hedeflemekte ve bu özelliği ile diğer çalışmalardan ayrılarak yenilikçi yönünü ortaya koymaktadır.
Yine bugüne kadar yapılan çalışmalar akademik sahada kalmış ve sadece ilgili alanda çalışan uzmanlara hitap ederken, bizim projemizin başarıyla sonuçlanması hâlinde ortaya çıkacak ürün Türkiye’de bir hak ihlaline uğradığını düşünen herkese hitap etmekte ve genel bir fayda sağlama potansiyeli taşımaktadır. Bu kapsamda, ilk defa bir mahkeme kararının tahmin edilmesine yönelik yapay zekâ temelli, zaman ve mekândan bağımsız olarak kullanılabilir, ücretsiz bir internet sitesinin tasarlanması ve hizmete sunulması hedeflenmektedir. Projenin bugüne kadar yapılan çalışmalardan en önemli farklılığını ve yenilikçi yönünü de bu ürün oluşturmaktadır.
Literatürde yer alan diğer çalışmalardan farklı olarak, bu proje Anayasa Mahkemesi kararlarında yer alan sadece “Olay ve Olgular” adlı başlığın makineye öğretilmesinden yola çıkarak hak ihlali yönündeki bireysel başvurulara mahkemenin muhtemel olarak hangi yönde karar vereceğini tahmin etmeyi amaçlamaktadır. Bunun yanında, birçok çalışmada sadece belli başlı haklar inceleme altına alınırken, bu projede herhangi bir sınıflandırmaya gidilmeksizin yekûn olarak mahkeme kararları yapay zekâya öğretilecek ve yine test için kullanılacak mahkeme kararları da rastgele seçilerek sistemin “genel” başarısı ölçülmeye çalışılacaktır.
YÖNTEM
Kurumsal düzeyde karar verme süreçlerine etkili olan verilerin büyük bir kısmı yapısal olmayan formattadır (Sharda vd. 2014). Metin verileri ise yapısal olmayan bu veri yığını içerisinde kritik bir yoğunluğa sahiptir ve toplanması, işlenmesi ve karar verme sürecinden efektif bir şekilde kullanılabilmesi için bir dizi yapısal adımın yürütülmesi gerekmektedir. Metin madenciliği (analitiği), yapısal olmayan içeriklerin yapısal ve sayısal hale döndürülerek veri analitiği süreçlerine hazır hale getirilmesi sürecidir ve makine öğrenmesi, doğal dil işleme, semantik, veri madenciliği ve istatistik gibi birçok bilimin ara kesitinde önemli bir rol üstlenmektedir. Özetleme, topik modelleme, duygu analizi gibi birçok kullanım alanı olan metin madenciliğinde (Jo, 2018; Zhai & Massung, 2016; Aggrawal & Shai, 2012) belki de üzerinde durulması gereken en önemli konu doğal dil işleme süreci ve bu yöntemin Türkçe metinlere uygulanabilirliğidir.
Doğal dil işleme, kelimelerin cümle içerisindeki konumu, anlamı, cümle içerisinde ifa ettiği görev gibi birçok unsurun incelenmesi suretiyle bilgisayarların doğal dili anlamasını sağlayan tekniklerin bütünü olarak değerlendirilebilir. Söz dizilimi (syntax), dil bilimi (morphology) ve anlambilim (semantik) NLP çalışmaları için temel oluşturan bilim dallarıdır (Zhai & Massung, 2016). Ayrıca, yüksek miktardaki bilgiyi bahse konu bilim dallarının kuralları ekseninde işlemek ve anlamanın bir gereksinimi olarak makine öğrenmesi (istatistiksel veya yapay zekâ tabanlı) yöntemini kullanmak NLP için çok değerli bir yaklaşımdır.
Metin madenciliği yaklaşımları çok farklı dillerde yüksek başarımla uygulanabilmektedir. Fakat Türkçe’nin eklemeli ve zengin biçimsel dil yapısı, başta doğal dil işleme gibi metin madenciliği yapılarının uygulanmasında önemli bir problem alanı oluşturmaktadır (Çetin & Eryiğit, 2018). Doğal dil işleme çalışmalarında ön işleme aşamalarında yürütülen işaretleme, konuşma bölümü etiketleme, gövdeleme ve anlamsal köke inme aşamalarında eklemeli dil yapısı ile başa çıkabilmek sürecin başarısını doğrudan etkilemektedir. Ayrıca deyimler ve atasözleri, metaforlar ve ironiler açısından çok zengin bir dil olan Türkçe’nin NLP ile analiz edilmesi için kapsamlı bir sözlüğe veya çok geniş çerçevede öğrenme gerçekleştiren tekniklere ihtiyacı olduğu muhakkaktır (Oflazer & Saraçlar, 2018).
Metin madenciliği yapısal olmayan içeriklerin yapısal hale döndürülerek veri madenciliği yaklaşımları yardımıyla analiz edilmesini içeren bir süreçtir. Bu süreç veri setinin oluşturulması, verilerin ön işlenmesi, boyut azaltma ve özellik çıkarımı ile veri madenciliği yaklaşımları anlamlı sonuçlara döndürülmesi (sınıflandırma) aşamalarını içermektedir.

Şekil 1. Proje aşamaları
Verinin Elde Edilmesi
Diğer madencilik süreçlerine benzer şekilde, metin madenciliği uygulamalarında ilk aşama verinin elde edilmesidir. Bu anlamda çalışmamızda açık olarak paylaşılan Anayasa Mahkemesi Bireysel Başvuru sonuçlarının dokümanları derlem oluşturacak şekilde https://kararlarbilgibankasi.anayasa.gov.tr/ web sitesinden HTML veri elde edilecek ve istenen başlıklardaki metinler toplanacaktır. Anayasa Mahkemesi’nin kararlarında temel olarak altı bölüm bulunmaktadır: “Başvurunun konusu”, “başvuru süreci”, “olay ve olgular”, “ilgili hukuk”, “inceleme ve gerekçe” ve son olarak “hüküm”. İlk bölümde, kısaca hangi gerekçelerle başvurunun gerçekleştirildiği ve hangi hakların ihlal edildiğinin iddia edildiği belirtilmektedir. Bir sonraki bölümde ise, bireysel başvuru tarihinden itibaren başvurunun karar sürecinden önce geçtiği aşamalar yer almaktadır. “Olay ve olgular” isimli üçüncü bölümde, başvuru formunda ve eklerinde ifade edildiği şekliyle ilgili olaylar belli bir düzen içerisinde sıralanmaktadır. Devam eden dördüncü bölümde ise, olaya uygulanabilecek kurallar ve mahkeme içtihatları yer almaktadır. “İnceleme ve gerekçe” isimli beşinci bölüm, mahkemenin her bir hak ihlali iddiasını, tarafların konuyla alâkalı görüşlerini ayrı ayrı paylaştıktan sonra gerek kabul edilebilirlik gerekse esas yönünden değerlendirdiği ve kanaatini açıkladığı bölümdür. Son olarak mahkeme “hüküm” isimli altıncı bölümde, iddialarla alâkalı nihâi kararını açıklamaktadır. Bu projede, ilgili kararların tamamı değil, sadece “olay ve olgular” adlı bölümü kullanılacaktır. Bu ayıklamadan sonra, bu metinler öncelikle kabul edilebilirlik için etiketlenecektir. Ardından kabul edilebilir olanlar ise hak ihlali için evet ve hayır olarak tekrar etiketlenecektir. HTML veriler txt uzantılı dosyalarda kayıt dosya adı olarak karar türü ve karar numarası ile kaydedilecektir.
Veri Önişleme
Veri analizi süreçlerinin görece en önemli adımı, veri kalitesini artırmak adına yapılan ön işleme çalışmalarıdır. Bu çalışmalar en fazla süreyi almakla birlikte, yapılacak yanlış bir işlemin yapısal soruna dönerek analiz başarımını doğrudan etkileyebildiği söylenebilir. Metin madenciliği çalışmalarında da durum farklı değildir. Bu aşamada, genelde metin verisindeki gürültünün alınmasına odaklanılırken, aslında temel amaç metnin bilgi çıkarımı aşaması öncesinde sayısallaştırılarak analiz süreçlerinin gereksinimlerini karşılayabilecek şekilde dönüştürülmesidir. Veri ön işleme sürecinin temel çıktısı, tutarlı, alâkalı, yorumlanabilir, tam, hatasız ve tarafsız veya genel olarak “kaliteli” bir veri seti oluşturmaktır. Metin veri ön işleme süreçleri 4 temel adımda gerçekleştirilir.
• Birimleştirme: Bu aşamada metinler en küçük birimine (kelime veya kelime grupları) ayrılır. Bu işlem sırasında ise beyaz boşluk temizlenirken, noktalama işaretleri, sayılar ve simgeler işaretlere (token) dönüştürülerek ayrıştırılır. Ayrıca analizcinin ihtiyaç ve isteklerine göre n gruplu (n-gram) kelime gruplarına bölme işlemi de yine bu aşamada gerçekleştirilir (Jo, 2018; Anandarajan, Hill & Nolan, 2019).
• Standartlaştırma: Önceki adımdan gelen liste isteğe bağlı olarak sayılar, simgeler, emojiler vb. kelime dışı unsurlardan temizlenir. Ayrıca bütün büyük harfler küçük harflere döndürülür (Anandarajan, Hill & Nolan, 2019). Bu aşamada python yazılım dilindeki “replace” ve “lambda” fonksiyonları kullanılabilir.
• Filtreleme: Standart içerik bu aşamada çok anlamlı olmayan kelimelerden (durdurma kelimeleri) temizlenir (Jo, 2018; Anandarajan, Hill & Nolan, 2019). Bunun için python yazılım dilindeki “NLTK” kütüphanesinde yer alan Türkçe durdurma kelimeleri listesi kullanılır.
• Dilsel Önişleme: En kapsamlı ve görece en zor işlemlerin yapıldığı bu adımda kelimeler eklerinden temizlenerek köklerine indirgenir. Ayrıca bu kelimelerin cümle içerisindeki görevi, kelime ve tamlamaların tipleri yine bu aşamada cümle bölümü etiketleme yöntemi ile gerçekleştirilir (Aravi, 2014; Weiss vd., 2005; Anandarajan, Hill & Nolan, 2019, Cady, 2017). Bu aşama sonunda her bir sözcük ve sözcük öbeğine farklı öznitelikler eklenmiş olur. Türkçe metinlerde köke inme işlemi için “zemberek” kütüphanesi kullanılmıştır.
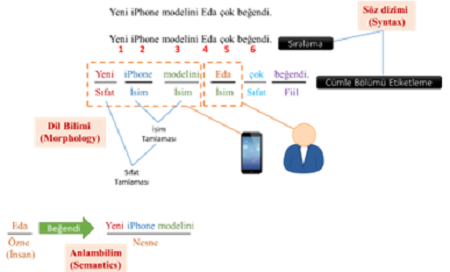
Şekil 2. Veri önişleme örneği
Veri önişleme aşamalarından sonra temizlenmiş (işlenmiş) veri öznitelik seçimi ve sayısallaştırma için sonraki adıma çıktı olarak gönderilir.
Öznitelik Çıkarımı
Veri önişleme süreci sonrasında veri setindeki her bir sözcük için çok sayıda öznitelik oluşturulmuştur (sözcük tipi, cümle içindeki görevi, cümle içerisindeki sırası, önceki sözcük, sonraki sözcük vb.). Fakat hazırlanmış olan bu tablo bilgi çıkarımı (sınıflandırma) aşaması için uygun olmayacaktır. Bu aşamada öncelikle veri seti vektörel bir yapıya döndürülmelidir (Berry & Kogan, 2010). Bu işlem için çok sayıda yöntem kullanılabilmesine rağmen, en çok tercih edilen yöntem Terim Frekansı – Ters Dokuman Frekansı (TF-IDF) yöntemdir (Jo, 2018). TF-IDF bir sözcüğün bulunduğu doküman içerisinde ve toplam derlem içerisindeki frekansına bağlı bir değer hesaplar; hesaplanan değer ile birlikte o sözcüğün ne ölçüde bilgi taşıdığı (önemli olduğu) belirlenmiş olur.
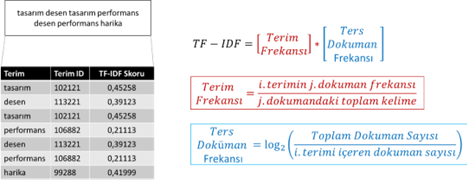
Şekil 3. Öznitelik çıkarım örneği
TF-IDF yöntemi, öznitelik seçiminde “filtreleme yöntemi” olarak değerlendirilir ve görece en çok kullanılan yöntemdir. Diğer bilinen filtreleme yöntemleri ise Bilgi Kazanımı, Ki Kare Skoru, Karşılıklı Bilgi, Ağırlıklı Logaritmik Olasılıklı Oran, GINI ve korelasyon katsayısıdır (Li, Xia, Zong & Huang, 2009; Haddi vd., 2013; Varela, Martins, Aquiar &Fiqueiredo, 2013; Hung, Alfred & Ahmad Hijazi, 2015; Yousefpour, Ibrahim & Hamed, 2017; Poria vd., 2018; Sailunaz vd., 2018; Yue vd., 2019). Bunların dışında gömülü (makine öğrenmesi ve optimizasyon temelli) ve sarmalayıcı (alt modüllere ayırarak performans ayrıştırma) yöntemler de literatürde tercih edilebilmektedir (Budak, 2018; Çetin & Eryiğit, 2018)
Öznitelik çıkarımı aşamasında boyut azaltma amacıyla tekil değer ayrıştırma (Singular Value Decomposition – SVD) sıklıkla kullanılır (Anandarajan, Hill & Nolan, 2019). SVD veri setini ayrıştırırken öznitelikleri seçerek boyutları düşürmek için, Saklı Semantik İndeksleme (Latent Semantic Indexing – LSI) (Shmueli vd, 2017; Kantardzic, 2011; Aggarwal & Zhai, 2012) ve Saklı Dirilecht Konumlandırma (Latent Dirichlet Allocation – LDA) (Anandarajan, Hill & Nolan, 2019; Aggarwal & Zhai, 2012; Berry & Kogan, 2010) gibi yöntemler tercih edilir. Veri setinden bu yöntemler hibrit olarak boyut azaltma ve öznitelik seçiminden kullanılması öngörülmektedir.
Sınıflandırma
Yöntemin son aşaması ise bilgi çıkarımını kapsar. Bu aşamada farklı yöntemler tercih edilebilmesine rağmen en çok tercih edilen yöntem “sınıflandırma”dır. Bu çalışmada, her bir başvurunun olası kabulü ikili sınıflandırma ile değerlendirilecektir. İkili sınıflandırmada bir makine öğrenmesi seti vasıtasıyla öğrenen bir algoritma sadece iki değere sahip çıktı değişkeninin değerini tahmin etmeye çalışır (Jo, 2018). Bu çalışmada sınıflandırma iki aşamada gerçekleştirilecektir. İlk aşamada metinler kabul edilebilirlik açısından olumlu ya da olumsuz olarak değerlendirilecek ve olumlu değerlendirilen metinler ikinci aşamada hak ihlali olup olmadığı (Esas-İhlal/Esas İhlal Olmadığı) durumuna göre tekrar sınıflandırmaya tabi tutulacaktır.
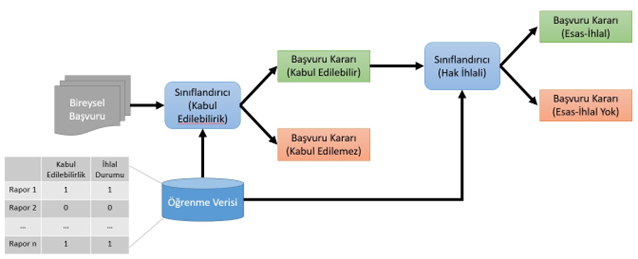
Şekil 4. Sınıflandırma işlemi örneği
İkili sınıflandırma spam mail filtreleme ve duygu analizi gibi konularda metinleri iki gruba ayırmada yıllardır kullanılmaktadır (Aggarwal & Zhai, 2012). Veri önişleme ve öznitelik seçme aşamaları sonucunda sayısallaştırılmış bir veri seti söz konusu olduğundan teknik olarak herhangi bir denetimli makine öğrenmesi tekniği ile sınıflandırma yapılabilmektedir. Bu çalışmada, çok sayıdaki teknik ayrı ayrı uygulanarak en yüksek başarımı sağlayan makine öğrenmesi yöntemi ile sınıflandırma yapılarak bilgi çıkarımı gerçekleştirilecektir. Öncelikle en az 1200 kabul edilebirlik kararına ait metinlerin ve 1200 de kabul edilemezlik kararlarına ait metinlerin sınıflandırılması yapılacaktır. Ardından da kabul edilebilir karar metinlerinden en az 600 hak ihlali varlığı içeren ve en az 600 de hak ihlali içermeyen karar metinleri sınıflandırılacaktır. Böylece kabul edilebilir olan kararların ikinci bir ikili sınıflandırmaya tabi tutulacakken kabul edilemez kararlar başka bir sınıflandırmaya tabi tutulmayacaktır.
HAKTAM Web Sistemi (Arama Motoru)
Yukarıdaki tüm işlemler yapıldıktan sonra elde edilen yapay zekâ modeli web tabanlı bir sistem üzerinde çalışır hale getirilecektir. Böylece herkese açık kullanım imkânı olan bir Hak İhlali Karar Tahmin Motoru (HAKTAM) oluşturulacaktır. İsteyen tüm kullanıcılar bu sisteme erişerek başvurusu ile ilgili olayı ve olguları metin olarak yazacaktır. Ardından sistem arka tarafta yapay zekâ yöntemleri ile öğrendiklerini kullanacak ve başvurunun öncelikle kabul edilebilir ya da kabul edilemez olmasını tahmin edecektir. Ardından yalnızca kabul edilebilir başvurular için aynı metin tekrardan incelenerek hak ihlali içerip içermediğine yönelik tahmini sunacaktır. Böylece tahmin motoru kabul edilemez metinler için yalnızca kabul edilemez bilgisini son kullanıcıya sunacak olup kabul edilebilir metinler için ise hem kabul edilebilir olduğunu hem de hak ihlali olup olmadığı bilgisini son kullanıcıya sunacaktır. Sistemi kullanan kişilerin hiçbir verisi kayıt altına alınmayacaktır. Sistemin daha iyi öğrenmesini sağlamak için yılda bir kere AYM sitesinden veri çekilmesi ve diğer tüm işlemler en baştan yapılacaktır. Böylece sistem kendisini sürekli güncellemiş olacaktır.
Ön Çalışma
Anayasa Mahkemesinin Kararlar Bilgi Bankası adlı web sitesi üzerinden vermiş olduğu tüm kararlar herkese açık olarak sunulmaktadır. Burada çeşitli başlıklar vardır ve yapay zekâ ile incelenecek başlık olarak “Olaylar ve Olgular” başlığı belirlenmiştir. Proje için yapılan ön çalışmada Anayasa Mahkemesinin 12.10.2021 tarihine kadar toplam 9270 karar verdiği görülmüştür. Bu kararların başvuru sonucuna göre nasıl farklılaştığı yapılan inceleme sonucu aşağıdaki gibi görülmüştür.

Tablo 1. Başvuru sonuçlarına göre AYM karar sayıları
Veri setinin yukarıda verilen tabloda görüldüğü üzere dengesiz dağılım gösterdiği görülmektedir. Bu nedenle çalışmada ihlal olmayanların tümünü toplamak ve ihlal kararlarından ise ihlal olmayanların sayısı kadarını rastgele seçerek toplamak düşünülmektedir.
Karar Tahmin Motoru
Anlık Tahmin
— Tanıtım —
.gif)
Tanıtım 1
.gif)
Tanıtım 2
.gif)
Tanıtım 3
.gif)
Tanıtım 4
.gif)
Tanıtım 5
.gif)
Tanıtım 6
.gif)
Tanıtım 7
.gif)
Tanıtım 8
.gif)
Tanıtım 9
İletişim
Proje Hakkında
Projemiz hakkındaki tüm sorularınızı cevaplamak için buradayız. Her tür sorunuzu cevaplamak ya da katkılarınızı duymak isteriz.